Gutenberg LLM

Overview
Have you ever wanted to chat with a classic novel, like Dostoyevsky’s Crime and Punishment or discern which of the Confucian Analects best pertains to your present life events (perhaps ”Never give a sword to a man who can't dance”)?
Gutenberg LLM allows you to query and chat with books in from the entirety of Project Gutenberg’s archives of nearly 80,000 books in the public domain.
Try it out at https://gutenberg.anmiller.com
Design
Overview
Gutenberg LLM is a fullstack TypeScript NextJS application, using the Vercel AI SDK and deployed at https://gutenberg.anmiller.com via Vercel. The high-level architecture is shown below.
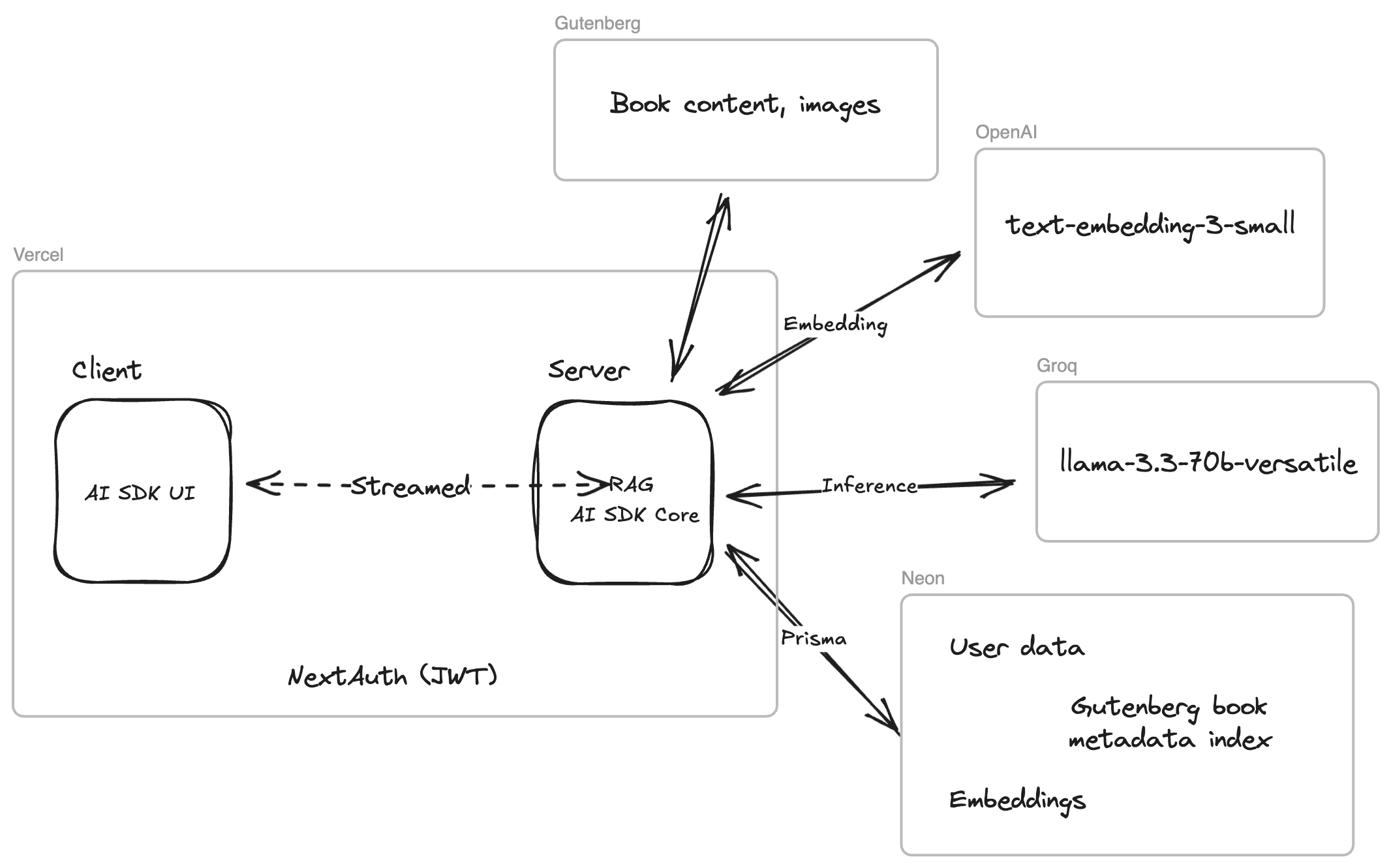
UI
Frontend components are shadcn. Client-server interaction is primarily accomplished through React server actions, with minimal client-side fetching. A standard email-based (Resend as the SMTP provider) and social (Google OAuth) JWT refresh token authentication flow is implemented with Auth.js.
RAG
For embeddings, the OpenAI text-embedding-3-small is used due to its low cost (text-embedding-3-large produces comparable results). Per the 8,192 token limit, texts are first chunked and fed. Also considered was Cohere’s embed-english-v3.0 due to its much larger context window for embeddings.
For inference, model used is llama-3.3-70b-versatile served by Groq. Llama 3.3 70B Versatile 128k is a natural choice for inference on large texts, due to its large context window that can handle up to a few hundred pages of a book in RAG results.
Application data, embeddings of books from the Project Gutenberg archives, and are stored with using pgvector, hosted on a serverless Postgres instance via Neon and connected with Prisma ORM.
Gutenberg Book Search
Project Gutenberg publishes a weekly index (pg_catalog.csv) of archive metadata. Since it’s a small index, it was simple to apply it as a lookup table to enable ergonomic queries by title, author, etc. for downloading book content from gutenberg.org.
Alternatives Considered
The most opinionated technical choice was to rely on the Vercel AI SDK and a fully TypeScript stack, compared to a Python stack such as FastAPI, LangChain, etc. TypeScript was preferred to reduce the code and deployment surface area due to the narrow scope of this project. Additionally the Node ecosystem for RAG is substantial, with language bindings for the general-purpose RAG implemented here. For a larger project or with more granular inference goals, I would generally choose Python. A disadvantage of using AI SDK Core was the lack of access to the formidable Python statistical library ecosystem, (e.g., such as for implementing kMeans clustering for improved book summaries). That said, the AI SDK UI especially is still a great choice for frontend.
Another decision was to use the pgvector Postgres extension rather than a dedicated vector database, e.g., Pinecone. pgvector has good performance at small-to-medium scales, and supports HNSW indexing, cosine similarity etc. So for some reduced scalability compared to a dedicated vector database, pgvector had the advantage of being a natural extension of Postgres and the rest of the stack, and maintaining low (or at least equivalent to other queries)-latency given its the same database we’re using in general.
Finally the deployed application relies on the an edge deployment network, which is great for caching and latency but not ideal for the heavier tasks, namely writing the generated embeddings to the database. You’ll notice the embeddings generation and writing on page load takes seconds to ~minute upper bound on large books. This is primarily a consequence of doing heavy lifting from small edge nodes. Apportioning a dedicated server instead of running the writing of book embeddings on demand via edge nodes would be an obvious performance win.